集合
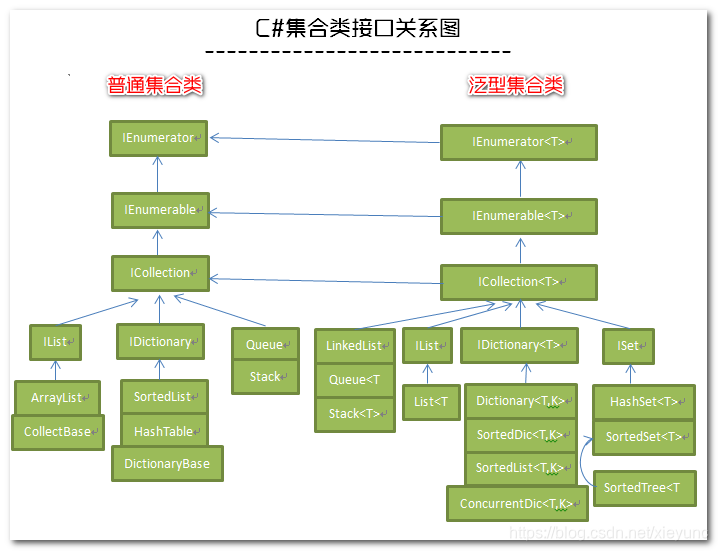
推荐使用场景:
| 集合类型 | 是否顺序排列 | 是否连续存储 | 访问时间复杂度 | 操作时间复杂度 | 直接访问方式 | 使用场景 |
|---|---|---|---|---|---|---|
Array | 是 | 是 | O(1) | 插入/删除: O(n) | 索引 | 用于已知大小和类型固定的元素集合,性能高,适用于频繁访问和较少修改的场景。 |
List<T> | 是 | 是 | O(1) | 插入/删除: O(n) | 索引 | 动态大小的数组,适用于需要动态调整元素数量的场景,常用于大多数需要顺序访问和偶尔插入/删除的场景。 |
SortedList<TKey, TValue> | 是 | 是 | O(log n) | 插入/删除: O(n) | 键或索引 | 需要按键排序且存储量较小时,适用于需要高效内存使用且偶尔进行查找和修改操作的场景。 |
LinkedList<T> | 是 | 否 | O(n) | 插入/删除: O(1) | 不支持索引 | 适用于需要频繁插入/删除操作且不需要随机访问的场景,例如队列或需要保持元素顺序的场景。 |
ImmutableList<T> | 是 | 是 | O(1) | 插入/删除: O(n) | 索引 | 适用于需要保持集合不变且能安全共享的场景,常用于并发编程或函数式编程。 |
Dictionary<TKey, TValue> | 否 | 否 | O(1) | 插入/删除: O(1) | 键 | 用于根据键快速查找值的场景,适用于键值对存储,如映射关系或查找表。 |
SortedDictionary<TKey, TValue> | 是 | 否 | O(log n) | 插入/删除: O(log n) | 键 | 需要按键排序的键值对集合,适用于需要按顺序存取键值对的场景。 |
ConcurrentDictionary<TKey, TValue> | 否 | 否 | O(1) | 插入/删除: O(1) | 键 | 线程安全的键值对集合,适用于多线程环境下需要快速查找和修改键值对的场景。 |
ImmutableDictionary<TKey, TValue> | 否 | 否 | O(1) | 插入/删除: O(log n) | 键 | 适用于需要不可变且线程安全的键值对集合,常用于并发编程中的共享数据。 |
HashSet<T> | 否 | 否 | O(1) | 插入/删除: O(1) | 不支持索引 | 用于存储不重复元素的集合,适用于需要快速查找和去重操作的场景。 |
SortedSet<T> | 是 | 否 | O(log n) | 插入/删除: O(log n) | 不支持索引 | 适用于需要排序且无重复元素的集合,适合用于需要自然排序且查找、插入效率较高的场景。 |
ConcurrentBag<T> | 否 | 否 | O(n) | 插入: O(1), 删除: O(n) | 不支持索引 | 线程安全的无序集合,适用于需要在多线程环境中收集和分发元素的场景。 |
Queue<T> | 是 | 否 | O(n) | Enqueue: O(1), Dequeue: O(1) | 不支持索引 | 先进先出(FIFO)集合,适用于排队、缓冲、任务调度等场景。 |
Stack<T> | 是 | 否 | O(n) | Push: O(1), Pop: O(1) | 不支持索引 | 后进先出(LIFO)集合,适用于需要后进先出的场景,如撤销操作、表达式求值等。 |
Array(数组)
数组的特点
数组的本质是一种引用类型的数据结构,它可以存储一组相同类型的元素,并在内存中以连续的方式分配空间。这些元素可以通过索引来访问,其中索引是基于零的。
数组具有以下属性:
1.数组可以是一维、多维或交错的。
2.声明数组变量时设置维度数。 创建数组实例时,将建立每个维度的长度。 这些值在实例的生存期内无法更改。
3.交错数组是数组数组,每个成员数组的默认值为null。
4.数组从零开始编制索引:包含 n 元素的数组从 0 索引到 n-1。
5.数组元素可以是任何类型,其中包括数组类型。
6.数组类型是从抽象的基类型 Array 派生的引用类型。 所有数组都会实现IList和IEnumerable。 可以使用 foreach 语句循环访问数组。 单维数组还实现了 IList<T> 和 IEnumerable<T>。
一维数组
一维数组的创建
1.指定长度的数组创建
// 创建一个长度为5的int数组,默认值为0
int[] numbers = new int[5];2.直接初始化数组
// 创建并初始化数组
int[] numbers = new int[] { 1, 2, 3, 4, 5 };
// 简化的初始化方法
int[] numbers = { 1, 2, 3, 4, 5 };3.使用Array.CreateInstance方法 在运行时动态创建数组,特别是在不知道数组类型或维数的情况下
// 创建一个长度为5的int类型数组
Array dynamicArray = Array.CreateInstance(typeof(int), 5);
// 设置第一个元素的值
dynamicArray.SetValue(42, 0);
// 获取第一个元素的值
int value = (int)dynamicArray.GetValue(0);一维数组的遍历
int[] numbers = { 1, 2, 3, 4, 5 };
// 使用for循环遍历
for (int i = 0; i < numbers.Length; i++)
{
Console.WriteLine(numbers[i]);
}
// 使用foreach遍历
foreach (int number in numbers)
{
Console.WriteLine(number);
}常用方法
多数操作可采用LINQ,此处不再列出
//排序
//正序
Array.Sort(numbers);
//反转数组
Array.Reverse(numbers);
//查找元素
int index = Array.IndexOf(numbers, 3); // 查找值为3的元素的索引
//清空数组
Array.Clear();
Array.Clear(numbers, 0, numbers.Length);多维数组
多维数组的创建
1.指定长度的数组创建
// 创建一个3x3的二维数组
int[,] matrix = new int[3, 3];
// 创建一个3x3x3的二维数组
int[,,] matrix = new int[3, 3, 3];2.直接初始化数组
// 创建并初始化数组
int[,] matrix = new int[,]
{
{ 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 }
};
int[,,] matrix = new int[,,]
{
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
};
// 简化的初始化方法
int[,] matrix =
{
{ 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 }
};
int[,,] matrix =
{
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
};3.使用Array.CreateInstance方法 在运行时动态创建数组,特别是在不知道数组类型或维数的情况下
// 创建一个长度为5x5x5的int类型数组
Array dynamicArray = Array.CreateInstance(typeof(int), 5, 5, 5);
// 设置第0, 0, 0个元素的值
dynamicArray.SetValue(42, 0, 0, 0);
// 获取第0, 0, 0个元素的值
int value = (int)dynamicArray.GetValue(0, 0 ,0);注意
多维数组的长度(matrix.Length)为:X x Y x Z!!
多维数组的遍历
int[,,] matrix = new int[,,]
{
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
{
{1,2,3},
{1,2,3},
{1,2,3}
},
};
// 使用for循环遍历
for (int i = 0; i < matrix.GetLength(0); i++)
{
for (int j = 0; j < matrix.GetLength(1); j++)
{
for (int k = 0; k < matrix.GetLength(2); k++)
{
Console.WriteLine(matrix[i,j,k]);
}
}
}
// 使用foreach遍历
foreach (int number in matrix)
{
Console.WriteLine(number);
}常用方法
//排序、反转、查找元素等操作只有一维数组可使用
//清空数组
Array.Clear();
Array.Clear(numbers, 0, numbers.Length);交错数组
交错数组的创建
1.指定长度的数组创建
int[][] jaggedArray = new int[3][]; // 创建一个有3个子数组的锯齿数组
// 初始化每个子数组
jaggedArray[0] = new int[2]; // 第一个子数组有2个元素
jaggedArray[1] = new int[3]; // 第二个子数组有3个元素
jaggedArray[2] = new int[4]; // 第三个子数组有4个元素2.直接初始化数组
// 创建并初始化数组
// 不能简化初始方法
int[][] jaggedArray = new int[][]
{
new int[] { 1, 2 },
new int[] { 3, 4, 5 },
new int[] { 6, 7, 8, 9 }
};3.使用Array.CreateInstance方法 在运行时动态创建数组,特别是在不知道数组类型或维数的情况下
// 创建一个长度为2x3x4的int类型数组
Array dynamicArray = Array.CreateInstance(typeof(int), 2, 3, 4);
// 设置第0, 0, 0个元素的值
dynamicArray.SetValue(42, 0, 0, 0);
// 获取第0, 0, 0个元素的值
int value = (int)dynamicArray.GetValue(0, 0 ,0);List(列表)
List(普通列表)
List 表示可由索引访问的强类型对象列表。
List<T>是一个通用(泛型)集合类,属于System.Collections.Generic命名空间, List的大小是动态的,当添加或删除元素时,它会自动调整容量。
容量
当使用默认构造函数创建一个空的List对象时,初始容量为0。但当第一次添加元素时,List的容量会扩大到足以容纳4个元素。随后,每次添加元素(Add,AddRange)时,如果当前容量不足,List的容量会翻倍增加,即每次增加的容量是原容量的两倍。
List的常用操作
//创建和初始化
// 创建一个空的List
List<int> numbers = new List<int>();
// 使用初始值创建List
List<int> numbers = new List<int> { 1, 2, 3, 4, 5 };
// 指定容量创建List
List<int> numbers = new List<int>(10); // 容量为10的空List
//添加元素
// 添加单个元素
numbers.Add(6);
// 添加多个元素
numbers.AddRange(new int[] { 7, 8, 9 });
// 插入元素到指定位置
numbers.Insert(2, 10); // 在索引2处插入10
// 访问元素
// 通过索引访问元素
int firstNumber = numbers[0]; // 获取第一个元素
// 修改指定索引处的元素
numbers[1] = 20; // 将第二个元素改为20
// 移除元素
// 移除指定元素(第一个匹配项)
numbers.Remove(10);
// 根据索引移除元素
numbers.RemoveAt(2);
// 移除指定范围内的元素
numbers.RemoveRange(0, 2); // 移除前两个元素
// 清空List
numbers.Clear(); // 移除所有元素
//查找元素
// 查找元素的索引
int index = numbers.IndexOf(20); // 查找第一个20的索引
// 查找符合条件的第一个元素
int number = numbers.Find(x => x > 5); // 查找第一个大于5的元素
// 查找所有符合条件的元素
List<int> result = numbers.FindAll(x => x > 5);
//遍历List
// 使用for循环遍历
for (int i = 0; i < numbers.Count; i++)
{
Console.WriteLine(numbers[i]);
}
// 使用foreach遍历
foreach (int number in numbers)
{
Console.WriteLine(number);
}
// 排序和反转
// 升序排序
numbers.Sort();
// 降序排序
numbers.Sort((a, b) => b.CompareTo(a));
// 反转List顺序
numbers.Reverse();
// 转换为数组
int[] array = numbers.ToArray();
// 获取子列表
List<int> sublist = numbers.GetRange(0, 3); // 获取从索引0开始的3个元素
// 检查是否包含某个元素
bool containsNumber = numbers.Contains(5); // 检查是否包含5
//跳过指定个数元素
numbers.Skip(0);
//取前几个元素
numbers.Take(1);其他用法未依次列出
多数操作可采用LINQ,此处也不再列出
SortedList(排序列表)
SortedList<TKey, TValue> 是 C# 中一个集合类,它既实现了 IDictionary<TKey, TValue> 接口,也实现了 ICollection<KeyValuePair<TKey, TValue>> 接口。它在键值对中按键排序并提供键和索引两种方式来访问元素。
SortedList的常用操作
基本类型作为Key
//创建
var sortedList = new SortedList<int, string>();
// 指定初始容量为10
var sortedList = new SortedList<string, int>(10);
// 不区分大小写的比较器
var sortedList = new SortedList<string, int>(StringComparer.OrdinalIgnoreCase);
//添加元素
sortedList.Add(1, "One");
sortedList.Add(3, "Three");
sortedList[2] = "Two"; // 使用索引器添加元素
// 访问元素
string value = sortedList[1]; // 通过键访问
string valueByIndex = sortedList.Values[0]; // 通过索引访问值
int keyByIndex = sortedList.Keys[0]; // 通过索引访问键
if (sortedList.TryGetValue(2, out string value))
{
Console.WriteLine(value);
}
// 更新元素
sortedList[1] = "Uno"; // 更新键为1的值
// 删除元素
sortedList.Remove(1); // 删除键为1的元素
sortedList.RemoveAt(0); // 删除索引为0的元素
//遍历 SortedList
foreach (var kvp in sortedList)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}
foreach (var key in sortedList.Keys)
{
Console.WriteLine($"Key: {key}");
}
foreach (var value in sortedList.Values)
{
Console.WriteLine($"Value: {value}");
}对象作为Key
IComparer 其他实现方式参考IComparer
//创建
//重写IComparer
var sortedList = new SortedList<Person, string>(Comparer<Person>.Create((x, y) => x.Age.CompareTo(y.Age)));
//添加 Key值不能重复
sortedList.Add(new Person
{
Age = 1,
Name = "张1"
}, "张1 value");
sortedList.Add(new Person
{
Age = 2,
Name = "张2"
}, "张2 value");
sortedList.Add(new Person
{
Age = 3,
Name = "张3"
}, "张3 value");
// 访问元素
// 按Key访问,其他属性不影响最终结果
var key = new Person
{
Age = 1,
Name = "张法师打发打发1"
};
var value = sortedList[key];
Console.WriteLine(value);//张1 value
string valueByIndex = sortedList.Values[1]; // 通过索引访问值
Console.WriteLine(valueByIndex);//张2 value
var keyByIndex = sortedList.Keys[0]; // 通过索引访问键
Console.WriteLine(keyByIndex);
//// 更新元素
sortedList[key] = "张1 value updated";
//// 删除元素
sortedList.Remove(key); // 删除键为1的元素
sortedList.RemoveAt(0); // 删除索引为0的元素
// 遍历 SortedList
foreach (var kvp in sortedList)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}
foreach (var k in sortedList.Keys)
{
Console.WriteLine($"Key: {k}");
}
foreach (var v in sortedList.Values)
{
Console.WriteLine($"Value: {v}");
}LinkedList(链表)
LinkedList<T> 是 C# 中的一个集合类,用于存储双向链表的数据结构。与 List<T> 等基于数组的集合不同,LinkedList<T> 使用节点来存储元素,并且每个节点都有指向前一个节点和后一个节点的引用。这使得它在插入和删除操作方面非常高效,但在随机访问元素时性能较低。
LinkedList的常用操作
var linkedList = new LinkedList<string>()
// 添加元素
linkedList.AddLast("A");
linkedList.AddLast("B");
linkedList.AddLast("C")
// 在特定位置添加元素
var node = linkedList.Find("B");
linkedList.AddAfter(node, "D");
// 遍历链表
foreach (var value in linkedList)
{
Console.WriteLine(value);
}
// 删除元素
linkedList.Remove("B");
// 删除第一个元素
linkedList.RemoveFirst();
// 删除最后一个元素
linkedList.RemoveLast();ImmutableList(不可变列表)
ImmutableList<T> 是 C# 中的不可变集合类,它属于 System.Collections.Immutable 命名空间。ImmutableList<T> 提供了一个不可变的列表数据结构,这意味着一旦创建后,它的内容不能被修改。所有修改操作(如添加、删除、更新元素)都会返回一个新的 ImmutableList<T> 实例,而不会改变原有的实例。
ImmutableList的常用操作
var list = ImmutableList<int>.Empty
.Add(1)
.Add(2)
.Add(3);
// 添加元素
// 返回一个新的 ImmutableList\<T> 实例,而不会改变原有的实例
var newList = list.Add(4);
// 删除元素
// 返回一个新的 ImmutableList\<T> 实例,而不会改变原有的实例
var updatedList = newList.Remove(2);
// 插入元素
// 返回一个新的 ImmutableList\<T> 实例,而不会改变原有的实例
var listWithInsert = updatedList.Insert(1, 99);
// 更新元素
// 返回一个新的 ImmutableList\<T> 实例,而不会改变原有的实例
var listWithUpdate = listWithInsert.SetItem(1, 100);
// 遍历
foreach (var item in listWithUpdate)
{
Console.WriteLine(item); // 输出: 1 100 99 4
}Dictionary(字典)
Dictionary(普通字典)
Dictionary 是 C# 中的一个通用集合,用于存储键值对。Dictionary<TKey, TValue> 允许通过键(TKey)来快速查找与之关联的值(TValue)。它是基于哈希表实现的,查找、添加和删除操作的平均时间复杂度为 O(1)。
Dictionary的常用操作
// 创建
Dictionary<int, string> dict = new Dictionary<int, string>();
// 创建并添加元素
Dictionary<int, string> dict1 = new Dictionary<int, string>
{
{11, "11"},
{12, "12"},
{13, "13"}
};
// 添加元素
dict.Add(1, "One");
dict.Add(2, "Two");
// 使用索引器添加元素
dict[3] = "Three";
// 访问元素
string value = dict[1];
Console.WriteLine(value); // 输出 "One"
// 使用 TryGetValue 方法可以安全地获取值
if (dict.TryGetValue(3, out string result))
{
Console.WriteLine(result);
}
// 检查键是否存在
if (dict.ContainsKey(2))
{
Console.WriteLine("Key 2 exists.");
}
// 使用 foreach 循环遍历 Dictionary 的键值对:
foreach (var kvp in dict)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}
// 删除元素
dict.Remove(1);
// 获取元素个数
var count = dict.Count();
// 获取所有键
foreach (var item in dict.Keys)
{
}
// 获取所有值
foreach (var item in dict.Values)
{
}SortedDictionary(排序字典)
SortedDictionary<TKey, TValue> 是 C# 中的一种集合类型,它和 Dictionary<TKey, TValue> 类似,也用于存储键值对,但与 Dictionary 不同的是,SortedDictionary 会自动对键进行排序。因此,在遍历 SortedDictionary 时,键是按升序排列的。
SortedDictionary 的特点 自动排序:键值对根据键自动排序,默认使用键的 IComparable<T> 接口实现,也可以通过自定义比较器进行排序。
基于平衡二叉树:SortedDictionary 的内部实现基于红黑树(平衡二叉树),这使得插入、删除和查找操作的时间复杂度为 O(log n)。
键的唯一性:键在 SortedDictionary 中必须是唯一的,不能包含重复的键。
SortedDictionary的用法与Dictionary的基本一致
自动排序
基本类型作为Key
//可以自定义Comparer,默认为类型本身的Comparer
SortedDictionary<int, string> sortedDict = new SortedDictionary<int, string>(Comparer<int>.Create((x, y) => y.CompareTo(x)));
sortedDict.Add(1, "One");
sortedDict.Add(3, "Three");
sortedDict.Add(2, "Two");
foreach (var kvp in sortedDict)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
//3 2 1
}对象作为Key
IComparer 其他实现方式参考IComparer
var sortedDict = new SortedDictionary<Person, string>(Comparer<Person>.Create((x, y) => x.Age.CompareTo(y.Age))); // 不区分大小写的比较器
//添加 (Key值不能重复)
sortedDict.Add(new Person
{
Age = 1,
Name = "张1"
}, "张1 value");
sortedDict.Add(new Person
{
Age = 2,
Name = "张2"
}, "张2 value");
sortedDict.Add(new Person
{
Age = 3,
Name = "张3"
}, "张3 value");
// 访问元素
// 按Key访问及排序,其他属性不影响最终结果
var key = new Person
{
Age = 1,
Name = "张法师打发打发1"
};
var value = sortedDict[key];
// 遍历
foreach (var kvp in sortedDict)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}
foreach (var k in sortedDict.Keys)
{
Console.WriteLine($"Key: {k}");
}
foreach (var v in sortedDict.Values)
{
Console.WriteLine($"Value: {v}");
}注意
与SortedList相比,SortedDictionary没有list特性,不可按索引访问、删除
ConcurrentDictionary(线程安全字典)
ConcurrentDictionary<TKey, TValue> 是 C# 中用于并发编程的一种线程安全的字典。它是 System.Collections.Concurrent 命名空间的一部分,专门设计用于在多线程环境中操作数据而不需要手动管理锁。
ConcurrentDictionary 的特点 线程安全:ConcurrentDictionary 是线程安全的,可以在多个线程中同时进行读写操作,而不需要显式的锁定操作。
高效并发操作:内部使用了分段锁定机制(分区锁定),允许多个线程同时访问不同部分的数据,从而提高了并发性能。
丰富的原子操作:提供了许多原子操作,如 AddOrUpdate、GetOrAdd 等,允许在单个操作中完成检查和修改操作,避免竞争条件。
自动扩展:随着数据的增加,ConcurrentDictionary 会自动扩展以容纳更多的数据,且不会阻塞其他线程的访问。
常见用法
// 创建
ConcurrentDictionary<int, string> concurrentDict = new ConcurrentDictionary<int, string>();
// 使用 TryAdd 方法添加元素
bool added = concurrentDict.TryAdd(1, "One");
if (added)
{
Console.WriteLine("Element added.");
}
// 使用 GetOrAdd 方法,如果键不存在,则添加新元素;如果键存在,则返回已有的值:
string value = concurrentDict.GetOrAdd(2, "Two");
Console.WriteLine(value); // 输出 "Two"
// 更新元素
// 这个方法会先检查字典中键 1 的当前值是否为 "One",如果是则将其更新为 "Uno"。
bool updated = concurrentDict.TryUpdate(1, "Uno", "One");
if (updated)
{
Console.WriteLine("Element updated.");
}
// 使用 AddOrUpdate 方法可以在一个操作中完成添加或更新:
// 如果键 1 不存在,则添加 "One" 作为值。
// 如果键 1 存在,则调用委托 Func<TKey, TValue, TValue> 来更新值。
string updatedValue = concurrentDict.AddOrUpdate(1, "One", (key, oldValue) => oldValue + "!");
Console.WriteLine(updatedValue); // 输出 "One!" 或者更新后的值
// 使用 TryRemove 方法删除元素:
bool removed = concurrentDict.TryRemove(1, out string removedValue);
if (removed)
{
Console.WriteLine($"Removed value: {removedValue}");
}
// 可以使用 foreach 循环遍历 ConcurrentDictionary,但请注意遍历期间集合可能会发生更改:
foreach (var kvp in concurrentDict)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}
// 清空字典中的所有元素
concurrentDict.Clear();ImmutableDictionary(不可变字典)
ImmutableDictionary<TKey, TValue> 是 C# 中的一种不可变字典,属于 System.Collections.Immutable 命名空间。与 Dictionary<TKey, TValue> 和 ConcurrentDictionary<TKey, TValue> 不同,ImmutableDictionary 在创建后是不可更改的,即一旦创建了一个 ImmutableDictionary,它的内容就无法被修改。任何对其进行的“修改”操作都会返回一个新的 ImmutableDictionary 实例,而不会改变原来的字典。
ImmutableDictionary 的特点 不可变性:一旦创建,ImmutableDictionary 的内容就不会改变,保证了线程安全性。
持久性数据结构:使用共享结构的方式来高效地管理多个版本的字典,而不会完全复制所有数据。每次“修改”时,仅创建变化部分的新副本,并共享未修改的部分。
线程安全:由于不可变性,ImmutableDictionary 在多线程环境中是天然线程安全的,不需要额外的同步机制。
常见用法
// 创建 ImmutableDictionary
ImmutableDictionary<int, string> immutableDict = ImmutableDictionary<int, string>.Empty;
// Create 创建
var immutableDict = ImmutableDictionary.Create<int, string>();
// 通过Dictionary创建
var mutableDict = new Dictionary<int, string>
{
{1, "One"},
{2, "Two"}
};
var immutableDict = mutableDict.ToImmutableDictionary();
// builder创建
var builder = ImmutableDictionary.CreateBuilder<int, string>();
builder.Add(1, "One");
builder.Add(2, "Two");
ImmutableDictionary<int, string> immutableDictFromBuilder = builder.ToImmutable();
// 使用 Add 方法添加元素:
// 返回一个新的 ImmutableDictionary 实例 newDict,原来的 immutableDict 不会被修改。
ImmutableDictionary<int, string> newDict = immutableDict.Add(1, "One");
// 使用 SetItem 方法更新元素
// 返回一个新的字典 updatedDict,其中键 1 的值被更新为 "Uno"
ImmutableDictionary<int, string> updatedDict = newDict.SetItem(1, "Uno");
// 使用 Remove 方法删除元素
// 返回的新字典 removedDict 不再包含键 1。
ImmutableDictionary<int, string> removedDict = updatedDict.Remove(1);
// 可以使用 AddRange 方法批量添加元素:
// 返回的新字典 batchAddedDict
var newItems = new[]
{
new KeyValuePair<int, string>(2, "Two"),
new KeyValuePair<int, string>(3, "Three")
};
ImmutableDictionary<int, string> batchAddedDict = immutableDict.AddRange(newItems);
// 遍历 ImmutableDictionary
foreach (var kvp in immutableDict)
{
Console.WriteLine($"Key: {kvp.Key}, Value: {kvp.Value}");
}Set(集合)
HashSet(Hash集合)
HashSet<T> 是 C# 中的一种集合类型,位于 System.Collections.Generic 命名空间。它是一个基于哈希表的集合,用于存储不重复的元素,并提供高效的查找、添加和删除操作。
HashSet<T> 的特点 无重复元素:HashSet<T> 不允许集合中包含重复的元素。添加一个已经存在的元素不会改变集合,并且不会引发异常。会保留第一个。
高效的查找:由于内部使用哈希表,HashSet<T> 的查找、添加和删除操作的时间复杂度平均为 O(1)。
无序集合:HashSet<T> 不保证元素的顺序,因此元素在集合中的顺序是不可预测的。如果需要排序功能,可以考虑其他集合类型,如 SortedSet<T> 或 List<T>。
集合操作:提供了集合操作方法,如交集、并集和差集等,支持数学集合操作。
常用操作
存基础类型
// 创建 HashSet
HashSet<int> hashSet = new HashSet<int>();
HashSet<int> hashSet = new HashSet<int> { 1, 2, 3};
// 添加元素
bool added = hashSet.Add(1);
bool addedAgain = hashSet.Add(1); // 不会添加,返回 false
// 删除元素
bool removed = hashSet.Remove(1);
// 检查元素是否存在
bool contains = hashSet.Contains(1);
// 遍历 HashSet
foreach (int item in hashSet)
{
Console.WriteLine(item);
}
// 查询(LINQ实现)
var res = hashSet.Where(r => r == 1);
var res = hashSet.First(r => r == 1);
// 集合操作
// 交集
HashSet<int> setA = new HashSet<int> { 1, 2, 3 };
HashSet<int> setB = new HashSet<int> { 2, 3, 4 };
setA.IntersectWith(setB); // setA 现在包含 { 2, 3 }
// 并集
HashSet<int> setA = new HashSet<int> { 1, 2, 3 };
HashSet<int> setB = new HashSet<int> { 3, 4, 5 };
setA.UnionWith(setB); // setA 现在包含 { 1, 2, 3, 4, 5 }
// 差集
HashSet<int> setA = new HashSet<int> { 1, 2, 3 };
HashSet<int> setB = new HashSet<int> { 2, 3, 4 };
setA.ExceptWith(setB); // setA 现在包含 { 1 }
// 对称差集
HashSet<int> setA = new HashSet<int> { 1, 2, 3 };
HashSet<int> setB = new HashSet<int> { 3, 4, 5 };
setA.SymmetricExceptWith(setB); // setA 现在包含 { 1, 2, 4, 5 }
// 清空集合
hashSet.Clear();存对象
class Person
{
public string Name { get; set; }
public int ID { get; set; }
public override bool Equals(object? obj)
{
return obj is Person person &&
ID == person.ID;
}
public override int GetHashCode()
{
return HashCode.Combine(ID);
}
}
//使用
//注意 这里一定要把IEqualityComparer的实现类作为参数传递进来
var hashSet = new HashSet<Person>()
{
new Person
{
ID = 1,
Name = "Name1"
},
//重复,被排除
new Person
{
ID = 1,
Name = "Name11"
},
new Person
{
ID = 2,
Name = "Name2"
}
}
var a = hashSet.First(r => r.ID == 1);//Name1
//所有操作基于IEqualityComparer
bool contains = hashSet.Contains(new Person
{
ID = 1,
Name = "up to you"
});
...SortedSet(排序集合)
SortedSet<T> 是 C# 中一个表示元素集合的类,它自动保持元素按顺序排序。SortedSet<T> 基于红黑树(平衡二叉树)实现,支持高效的插入、删除和查找操作。它不允许有重复的元素,因此每个元素在集合中都是唯一的。
自动排序:SortedSet<T> 中的元素按照自然排序顺序(默认情况下按升序)进行排序。
唯一性:不允许重复元素。如果尝试添加一个已经存在的元素,它将不会添加,并且不会引发异常。
高效的操作:常见的集合操作(如添加、删除、查找等)在 SortedSet<T> 中具有良好的性能,通常为 O(log n) 时间复杂度。
支持集合操作:支持多种集合操作,如并集(Union)、交集(Intersect)、差集(Except)等。
常用操作
存基础类型
// 创建
SortedSet<int> sortedSet = new SortedSet<int>();
// 或
SortedSet<int> hashSet = new SortedSet<int> { 2, 1, 3};
// 添加元素
sortedSet.Add(3);
sortedSet.Add(1);
sortedSet.Add(2);
// 这个元素不会被添加,因为它已经存在
sortedSet.Add(2);
foreach (int item in sortedSet)
{
Console.WriteLine(item);
// 1 2 3
}
//其他操作与hashSet类似
...存对象
//创建
//自定义比较器
var sortedSet = new SortedSet<Person>(Comparer<Person>.Create((x, y) => x.ID.CompareTo(y.ID)))
{
new Person
{
ID = 1,
Name = "张1"
},
//重复不被添加
new Person
{
ID = 1,
Name = "张11"
},
new Person
{
ID = 2,
Name = "张2"
},
new Person
{
ID = 3,
Name = "张3"
},
};
foreach (var item in sortedSet)
{
Console.WriteLine(item.Name);
// 张1 张2 张3
}
//其他操作与hashSet类似
...ConcurrentBag(线程安全无序集合)
ConcurrentBag<T> 是 C# 中用于存储对象的线程安全集合,属于 System.Collections.Concurrent 命名空间。它允许多个线程同时向集合中添加和删除对象,而不需要显式的锁定操作,这在多线程环境下非常有用。ConcurrentBag<T> 适合用于对顺序不敏感但需要高效多线程访问的场景。
线程安全:ConcurrentBag<T> 内部使用了线程安全机制,确保多个线程可以同时进行添加、删除等操作,而不会引发竞争条件或数据损坏。
无序集合:与 List<T> 不同,ConcurrentBag<T> 是一个无序集合,无法保证元素的顺序。
支持重复元素:与 HashSet<T> 和 SortedSet<T> 不同,ConcurrentBag<T> 允许包含重复元素。
适合并行处理:当多个线程需要频繁向集合中添加或从集合中移除对象时,ConcurrentBag<T> 提供了优异的性能。
常用操作
存基础类型
// 创建
ConcurrentBag<int> bag = new ConcurrentBag<int>();
// 或
ConcurrentBag<int> bag = new ConcurrentBag<int> { 2, 1, 3};
// 添加元素
bag.Add(3);
bag.Add(1);
bag.Add(2);
// 移除元素
// 使用 TryTake 方法可以从 ConcurrentBag<T> 中移除一个元素。此方法会返回一个布尔值,指示是否成功移除了元素。
int result;
if (bag.TryTake(out result))
{
Console.WriteLine($"Removed: {result}");
}
else
{
Console.WriteLine("Bag is empty");
}
// 使用 TryPeek 方法可以查看集合中的一个元素,但不移除它。
int peekResult;
if (bag.TryPeek(out peekResult))
{
Console.WriteLine($"Peeked: {peekResult}");
}
else
{
Console.WriteLine("Bag is empty");
}
// 并行添加元素
ConcurrentBag<int> bag = new ConcurrentBag<int>();
Parallel.For(0, 10, i =>
{
bag.Add(i);
});
// 遍历元素
foreach (var item in bag)
{
Console.WriteLine(item);
}
...Queue(队列)
Queue(普通队列)
Queue<T> 是 C# 中一种基于先进先出(FIFO)原则的集合类型,位于 System.Collections.Generic 命名空间中。它适合用于按顺序处理元素的场景,尤其是当你希望按照元素被添加的顺序进行处理时。
主要特性 先进先出 (FIFO):Queue<T> 确保最先添加的元素最先被处理(出队)。
动态大小:队列会根据需要动态调整大小。
线程不安全:Queue<T> 本身并不是线程安全的,如果在多线程环境下使用,需要手动同步访问或使用线程安全的替代方案如 ConcurrentQueue<T>。
应用场景
任务调度:适合按顺序处理任务的场景,如打印队列、任务执行等。
缓冲机制:用于临时存储待处理的数据流,并按顺序处理。
消息队列:在事件驱动系统中用于存储和处理消息。
常用操作
// 创建队列
Queue<int> queue = new Queue<int>();
// 入队
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
// 出队(删除)
int item = queue.Dequeue();
Console.WriteLine(item); // 输出 1
// 查看队头元素(不删除)
int firstItem = queue.Peek();
Console.WriteLine(firstItem); // 输出 2
// 检查队列中元素的数量
int count = queue.Count;
Console.WriteLine(count); // 输出 2
// 遍历队列
foreach (int i in queue)
{
Console.WriteLine(i);
}
// 清空队列
queue.Clear();ConcurrentQueue(线程安全队列)
ConcurrentQueue<T> 是 C# 中一种线程安全的队列实现,位于 System.Collections.Concurrent 命名空间中。它继承了标准 Queue<T> 的先进先出 (FIFO) 特性,同时保证了在多线程环境下的安全操作。
主要特性
线程安全:ConcurrentQueue<T> 允许多个线程同时进行入队和出队操作,而不会产生数据竞争或异常行为。
先进先出 (FIFO):与 Queue<T> 一样,ConcurrentQueue<T> 确保最先入队的元素最先被处理。
无锁实现:通过无锁算法实现高效的线程安全操作,适合高并发场景。
应用场景
多线程任务处理:当多个线程需要同时处理任务或数据时,ConcurrentQueue<T> 是理想选择。
日志收集:可以用于在高并发环境下收集日志信息,确保日志按顺序处理。
消息队列:在并发环境下,用于传递和处理消息。
常用操作
ConcurrentQueue<string> queue = new ConcurrentQueue<string>();
// 多线程入队
Parallel.For(0, 10, i =>
{
queue.Enqueue($"Item {i}");
});
// 多线程出队
Parallel.For(0, 10, i =>
{
if (queue.TryDequeue(out string item))
{
Console.WriteLine($"Dequeued: {item}");
}
});
// 查看剩余的队列元素
Console.WriteLine("Remaining items in queue:");
foreach (var item in queue)
{
Console.WriteLine(item);
}Stack(栈)
Stack(普通栈)
Stack<T> 是 C# 中一种基于后进先出(LIFO, Last-In-First-Out)原则的集合类型,位于 System.Collections.Generic 命名空间中。它类似于一叠盘子,最新添加的元素最先被移除。Stack<T> 非常适合用于需要反向处理数据的场景。
主要特性
后进先出 (LIFO):Stack<T> 确保最后添加的元素最先被处理。
动态大小:栈会根据需要动态调整大小,以容纳更多的元素。
非线程安全:Stack<T> 在多线程环境下使用时,需要手动同步访问。如果需要线程安全,可以考虑使用 ConcurrentStack<T>。
应用场景
表达式求值:在处理逆波兰表达式(后缀表达式)时,栈可以用于操作符和操作数的管理。
递归计算:在某些递归算法中,可以使用栈来替代系统调用栈,实现非递归的解决方案。
浏览器后退功能:用于管理用户的历史访问记录,以支持页面的前进和后退。
撤销操作:在应用程序中,栈可以用来管理用户操作的历史,以实现撤销功能。
常用操作
// 创建
Stack<int> stack = new Stack<int>();
// 入栈
stack.Push(1);
stack.Push(2);
stack.Push(3);
// 出栈(删除元素)
int item = stack.Pop();
// 输出 3
Console.WriteLine(item);
// 查看栈顶元素
int topItem = stack.Peek();
// 输出 2
Console.WriteLine(topItem);
// 检查栈中元素的数量
int count = stack.Count();
// 输出 2
Console.WriteLine(count);
// 遍历栈
// 输出 2, 1
foreach (int i in stack)
{
Console.WriteLine(i);
}
// 清空栈
stack.Clear();ConcurrentStack(线程安全栈)
ConcurrentStack<T> 是 C# 中一种线程安全的栈实现,位于 System.Collections.Concurrent 命名空间中。它继承了标准 Stack<T> 的后进先出 (LIFO, Last-In-First-Out) 特性,同时保证了在多线程环境下的安全操作。
主要特性
线程安全:ConcurrentStack<T> 允许多个线程同时进行入栈和出栈操作,而不会产生数据竞争或异常行为。
后进先出 (LIFO):与 Stack<T> 一样,ConcurrentStack<T> 确保最后添加的元素最先被处理。
无锁实现:通过无锁算法实现高效的线程安全操作,适合高并发场景。
应用场景
多线程任务处理:当多个线程需要同时处理任务或数据时,ConcurrentStack<T> 是理想选择。
日志收集:可以用于在高并发环境下收集日志信息,确保日志按顺序处理。
递归计算替代:在并发环境下,用于替代系统调用栈来实现非递归的算法。
常用操作
ConcurrentStack<string> stack = new ConcurrentStack<string>();
// 多线程入栈
Parallel.For(0, 10, i =>
{
stack.Push($"Item {i}");
});
// 多线程出栈
Parallel.For(0, 10, i =>
{
if (stack.TryPop(out string item))
{
Console.WriteLine($"Popped: {item}");
}
});BlockingCollection(阻塞集合)
BlockingCollection<T> 是 C# 中一种线程安全的集合类型,位于 System.Collections.Concurrent 命名空间中。它提供了对生产者-消费者模式的支持,可以在多线程环境下安全地添加和移除元素,并提供了阻塞和限流的功能。
主要特性
1.实现制造者-使用者模式。
2.通过多线程并发添加和获取项。
3.可选最大容量。
4.集合为空或已满时通过插入和移除操作进行阻塞。
5.插入和移除“尝试”操作不发生阻塞,或在指定时间段内发生阻塞。
6.封装实现 IProducerConsumerCollection<T> 的任何集合类型
7.使用取消标记执行取消操作。
8.支持使用 foreach的两种枚举:
8.1.只读枚举。
8.2.在枚举项时将项移除的枚举。
常用操作
// 创建 BlockingCollection
// 可以使用默认的构造函数创建一个 BlockingCollection<T>,默认情况下,它使用 ConcurrentQueue<T> 作为底层存储。
BlockingCollection<int> collection = new BlockingCollection<int>();
// 还可以指定最大容量,以限制集合中的最大元素数量。
BlockingCollection<int> collection = new BlockingCollection<int>(boundedCapacity: 10);
// 还可以指定要使用的集合类型。
// 可为先进先出 (FIFO) 行为指定 ConcurrentQueue<T>,也可为后进先出 (LIFO) 行为指定 ConcurrentStack<T>
BlockingCollection<string> bc = new BlockingCollection<string>(new ConcurrentBag<string>(), 1000 );
// 添加元素
// 使用 Add 方法将元素添加到集合中。如果集合已满且有最大容量限制,Add 方法将阻塞,直到有空间可用。
collection.Add(1);
collection.Add(2);
collection.Add(3);
// 非阻塞地添加 会立即返回一个布尔值,指示操作是否成功。
if (collection.TryAdd(4))
{
Console.WriteLine("Added successfully");
}
// 移除元素
// 使用 Take 方法从集合中移除并返回一个元素。如果集合为空,Take 方法将阻塞,直到有新元素可用
int item = collection.Take();
Console.WriteLine(item); // 输出 1
// 非阻塞地移除 会立即返回一个布尔值,指示操作是否成功。
if (collection.TryTake(out int result))
{
Console.WriteLine($"Taken: {result}");
}
// 标记完成添加
collection.CompleteAdding();
// 可以使用 GetConsumingEnumerable 方法遍历集合中的元素,这个方法会在处理元素时阻塞,直到集合被标记为完成。
foreach (var item in collection.GetConsumingEnumerable())
{
Console.WriteLine(item);
}
// 使用带有 CancellationToken 的 Add 和 Take 方法,可以支持对阻塞操作的取消。
CancellationTokenSource cts = new CancellationTokenSource();
try
{
collection.Add(5, cts.Token);
int item = collection.Take(cts.Token);
}
catch (OperationCanceledException)
{
Console.WriteLine("Operation was canceled.");
}示例 1(阻塞)
展示了如何添加和取出项,以便在集合暂时为空(取出时)或达到最大容量(添加时),或超过指定超时期限时,阻止相应操作。 注意,仅当已创建 BlockingCollection 且构造函数中指定了最大容量时,才会启用在达到最大容量时进行阻止的功能。
using System;
using System.Collections.Concurrent;
using System.Runtime.InteropServices;
using System.Threading;
using System.Threading.Tasks;
class Program
{
static void Main()
{
// Increase or decrease this value as desired.
int itemsToAdd = 500;
if (RuntimeInformation.IsOSPlatform(OSPlatform.Windows))
{
int width = Math.Max(Console.BufferWidth, 80);
int height = Math.Max(Console.BufferHeight, itemsToAdd * 2 + 3);
// Preserve all the display output for Adds and Takes
Console.SetBufferSize(width, height);
}
// A bounded collection. Increase, decrease, or remove the
// maximum capacity argument to see how it impacts behavior.
var numbers = new BlockingCollection<int>(50);
// A simple blocking consumer with no cancellation.
Task.Run(() =>
{
int i = -1;
while (!numbers.IsCompleted)
{
try
{
i = numbers.Take();
}
catch (InvalidOperationException)
{
Console.WriteLine("Adding was completed!");
break;
}
Console.WriteLine("Take:{0} ", i);
// Simulate a slow consumer. This will cause
// collection to fill up fast and thus Adds wil block.
Thread.SpinWait(100000);
}
Console.WriteLine("\r\nNo more items to take. Press the Enter key to exit.");
});
// A simple blocking producer with no cancellation.
Task.Run(() =>
{
for (int i = 0; i < itemsToAdd; i++)
{
numbers.Add(i);
Console.WriteLine("Add:{0} Count={1}", i, numbers.Count);
}
// See documentation for this method.
numbers.CompleteAdding();
});
// Keep the console display open in debug mode.
Console.ReadLine();
}
}示例 2(非阻塞)
演示如何添加和取出项以便不会阻止操作。 如果没有任何项、已达到绑定集合的最大容量或已超过超时期限,TryAdd 或 TryTake 操作返回 false。 这样一来,线程可以暂时执行其他一些有用的工作,并在稍后再次尝试检索新项,或尝试添加先前无法添加的相同项。 该程序还演示如何在访问 BlockingCollection<T> 时实现取消。
using System;
using System.Collections.Concurrent;
using System.Runtime.InteropServices;
using System.Threading;
using System.Threading.Tasks;
class ProgramWithCancellation
{
static int inputs = 2000;
static void Main()
{
// The token source for issuing the cancelation request.
var cts = new CancellationTokenSource();
// A blocking collection that can hold no more than 100 items at a time.
var numberCollection = new BlockingCollection<int>(100);
if (RuntimeInformation.IsOSPlatform(OSPlatform.Windows))
{
int width = Math.Max(Console.BufferWidth, 80);
int height = Math.Max(Console.BufferHeight, 8000);
// Preserve all the display output for Adds and Takes
Console.SetBufferSize(width, height);
}
// The simplest UI thread ever invented.
Task.Run(() =>
{
if (Console.ReadKey(true).KeyChar == 'c')
{
cts.Cancel();
}
});
// Start one producer and one consumer.
Task t1 = Task.Run(() => NonBlockingConsumer(numberCollection, cts.Token));
Task t2 = Task.Run(() => NonBlockingProducer(numberCollection, cts.Token));
// Wait for the tasks to complete execution
Task.WaitAll(t1, t2);
cts.Dispose();
Console.WriteLine("Press the Enter key to exit.");
Console.ReadLine();
}
static void NonBlockingConsumer(BlockingCollection<int> bc, CancellationToken ct)
{
// IsCompleted == (IsAddingCompleted && Count == 0)
while (!bc.IsCompleted)
{
int nextItem = 0;
try
{
if (!bc.TryTake(out nextItem, 0, ct))
{
Console.WriteLine(" Take Blocked");
}
else
{
Console.WriteLine(" Take:{0}", nextItem);
}
}
catch (OperationCanceledException)
{
Console.WriteLine("Taking canceled.");
break;
}
// Slow down consumer just a little to cause
// collection to fill up faster, and lead to "AddBlocked"
Thread.SpinWait(500000);
}
Console.WriteLine("\r\nNo more items to take.");
}
static void NonBlockingProducer(BlockingCollection<int> bc, CancellationToken ct)
{
int itemToAdd = 0;
bool success = false;
do
{
// Cancellation causes OCE. We know how to handle it.
try
{
// A shorter timeout causes more failures.
success = bc.TryAdd(itemToAdd, 2, ct);
}
catch (OperationCanceledException)
{
Console.WriteLine("Add loop canceled.");
// Let other threads know we're done in case
// they aren't monitoring the cancellation token.
bc.CompleteAdding();
break;
}
if (success)
{
Console.WriteLine(" Add:{0}", itemToAdd);
itemToAdd++;
}
else
{
Console.Write(" AddBlocked:{0} Count = {1}", itemToAdd.ToString(), bc.Count);
// Don't increment nextItem. Try again on next iteration.
//Do something else useful instead.
UpdateProgress(itemToAdd);
}
} while (itemToAdd < inputs);
// No lock required here because only one producer.
bc.CompleteAdding();
}
static void UpdateProgress(int i)
{
double percent = ((double)i / inputs) * 100;
Console.WriteLine("Percent complete: {0}", percent);
}
}非泛型集合(不推荐)
C# 中的非泛型集合类位于 System.Collections 命名空间中。与泛型集合类相比,非泛型集合类不提供类型安全,这意味着你可以将不同类型的对象存储在同一个集合中,这可能导致类型转换错误。因此,非泛型集合类现在较少使用,通常推荐使用泛型集合类(如 List<T>、Dictionary<T1, T2> 等),因为它们提供了更好的性能和类型安全。
常见的非泛型集合类有:
ArrayList(非泛型)
ArrayList 是一个动态数组实现,可以存储不同类型的对象。它提供了类似于数组的访问方式,但大小可以动态调整。
常用操作
using System.Collections;
ArrayList arrayList = new ArrayList();
arrayList.Add(1);
arrayList.Add("string");
arrayList.Add(DateTime.Now);
foreach (var item in arrayList)
{
Console.WriteLine(item);
}Hashtable(非泛型)
Hashtable 是一个基于哈希表的数据结构,用于存储键值对(key-value pairs)。每个键必须是唯一的
常用操作
using System.Collections;
Hashtable hashtable = new Hashtable();
hashtable["key1"] = "value1";
hashtable["key2"] = "value2";
foreach (DictionaryEntry entry in hashtable)
{
Console.WriteLine($"{entry.Key}: {entry.Value}");
}Queue(非泛型)
Hashtable 是一个基于哈希表的数据结构,用于存储键值对(key-value pairs)。每个键必须是唯一的
常用操作
using System.Collections;
Queue queue = new Queue();
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
while (queue.Count > 0)
{
Console.WriteLine(queue.Dequeue());
}Stack(非泛型)
Hashtable 是一个基于哈希表的数据结构,用于存储键值对(key-value pairs)。每个键必须是唯一的
常用操作
using System.Collections;
Stack stack = new Stack();
stack.Push(1);
stack.Push(2);
stack.Push(3);
while (stack.Count > 0)
{
Console.WriteLine(stack.Pop());
}比较器接口
IComparable 与 IComparer
IComparable<T> 和 IComparer<T> 是 C# 中两个重要的接口,用于定义对象之间的相等性比较规则。它们在集合排序、比较等场景中非常有用。
IComparable
一般IEquatable用于对象的接口实现,用于比较当前对象与另一个同类型的对象的大小关系。
var chenrui = new Person
{
ID = 1,
Name = "陈1"
};
var sevenchen = new Person
{
ID = 7,
Name = "陈7"
};
// 0: =
// <0: <
// >0: >
Console.WriteLine($"chenrui compare sevenchen: {chenrui.CompareTo(sevenchen)}"); // -1实现了该接口可以用作排序
var list = new List<Person>() { sevenchen, chenrui };
//ID: 7; Name: 陈 7
//ID: 1; Name: 陈 1
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
//ID: 1; Name: 陈 1
//ID: 7; Name: 陈 7
list.Sort();
// 或
var sortedList = list.Order();
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
var sortDict = new SortedDictionary<Person, string> { { sevenchen, sevenchen.Name }, { chenrui, chenrui.Name }, };
// 陈 1
// 陈 7
foreach (var item in sortDict)
{
Console.WriteLine($"ID:{item};Name:{item}");
}
var sortSet = new SortedSet<Person> { sevenchen, chenrui };
//ID: 1; Name: 陈 1
//ID: 7; Name: 陈 7
foreach (var item in sortSet)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}IComparer
相对于IComparable,IComparer一般作为判断相等的外部参数。 比如以下方式也可以实现排序:
class Person
{
public string Name { get; set; }
public int ID { get; set; }
}
public class PersonComparer : IComparer<Person>
{
int IComparer<Person>.Compare(Person? x, Person? y)
{
return (x?.ID ?? int.MinValue).CompareTo(y?.ID ?? int.MinValue);
}
}
//使用
var list = new List<Person>() { sevenchen, chenrui };
//ID: 7; Name: 陈 7
//ID: 1; Name: 陈 1
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
//ID: 1; Name: 陈 1
//ID: 7; Name: 陈 7
list.Sort(new PersonComparer());
// 或
var sortedList = list.Order(new PersonComparer());
// 不用实现IComparer的用法
list.Sort((x,y) => x.ID.CompareTo(y.ID));
list.Sort(Comparer<Person>.Create((x, y) => x.ID.CompareTo(y.ID)));
var sortedList = list.Order(Comparer<Person>.Create((x, y) => x.ID.CompareTo(y.ID)));
var sortedList1 = list.OrderBy(r => r.ID);
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
var sortDict = new SortedDictionary<Person, string>(new PersonComparer()) { { sevenchen, sevenchen.Name }, { chenrui, chenrui.Name }, };
// 不用实现IComparer的用法
var sortDict = new SortedDictionary<Person, string>(Comparer<Person>.Create((x, y) => x.ID.CompareTo(y.ID))) { { sevenchen, sevenchen.Name }, { chenrui, chenrui.Name }, };
//ID: 1; Name: 陈 1
//ID: 7; Name: 陈 7
foreach (var item in sortDict)
{
Console.WriteLine($"ID:{item};Name:{item}");
}
var sortSet = new SortedSet<Person>(new PersonComparer()) { sevenchen, chenrui };
var sortSet = new SortedSet<Person>(Comparer<Person>.Create((x, y) => x.ID.CompareTo(y.ID))) { sevenchen, chenrui };
//ID: 1; Name: 陈 1
//ID: 7; Name: 陈 7
foreach (var item in sortSet)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}IEquatable 与 IEqualityComparer
IEquatable<T> 和 IEqualityComparer<T> 是 C# 中两个重要的接口,用于定义对象之间的相等性比较规则。它们在集合操作、查找、去重等场景中非常有用。
IEquatable
一般IEquatable用于对象的接口实现,来判断当前对象与另一个同类型对象是否相等。 等同于重写对象的Equals方法。 如:
class Person : IEquatable<Person>
{
public string Name { get; set; }
public int ID { get; set; }
public bool Equals(Person? other)
{
return other != null && other.ID == ID;
}
}
//等同于
class Person
{
public string Name { get; set; }
public int ID { get; set; }
public override bool Equals(object? obj)
{
return obj is Person person &&
ID == person.ID;
}
}
var chenrui = new Person
{
ID = 1,
Name = "陈1"
};
var sevenchen = new Person
{
ID = 1,
Name = "陈7"
};
Console.WriteLine($"chenrui equal sevenchen: {chenrui.Equals(sevenchen)}");//true但是,仅通过实现Equals并不能实现set和list的去重(其他IEnumerable集合:queue、stack等类似)(contains除外) 如:
class Person : IEquatable<Person>
{
public string Name { get; set; }
public int ID { get; set; }
public bool Equals(Person? other)
{
return other != null && other.ID == ID;
}
}
var chenrui = new Person
{
ID = 1,
Name = "陈1"
};
var sevenchen = new Person
{
ID = 1,
Name = "陈7"
};
Console.WriteLine($"chenrui equal sevenchen: {chenrui.Equals(sevenchen)}");//True
var set = new HashSet<Person>() { chenrui, sevenchen };
Console.WriteLine("=======HashSet=======");
// ID:1;Name:陈 1
// ID:1;Name:陈 7
foreach (var item in set)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
Console.WriteLine($"set contains chenrui: {set.Contains(chenrui)}");//True
Console.WriteLine($"set contains sevenchen: {set.Contains(sevenchen)}");//True
Console.WriteLine("=======List=======");
// ID:1;Name:陈 1
// ID:1;Name:陈 7
var list = new List<Person>() { chenrui, sevenchen };
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
Console.WriteLine($"list contains chenrui: {list.Contains(chenrui)}");//True
Console.WriteLine($"list contains sevenchen: {list.Contains(sevenchen)}");//True
Console.WriteLine("=======Distincted List=======");
// ID:1;Name:陈 1
// ID:1;Name:陈 7
var distinctedList = list.Distinct();
foreach (var item in distinctedList)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}而判断相等的工作流程为:
哈希码比较:先调用对象的 GetHashCode() 方法,检查两个对象的哈希码。如果它们的哈希码不同,则认为这两个对象不相等,直接插入新对象。
精确比较:如果哈希码相同,会调用 Equals() 方法来比较这两个对象。如果 Equals() 返回 true,则认为两个对象相等,新对象不会被添加到集合中。
所以需要重写GetHashCode方法!!!
class Person : IEquatable<Person>
{
public string Name { get; set; }
public int ID { get; set; }
public bool Equals(Person? other)
{
return other != null && other.ID == ID;
}
public override int GetHashCode()
{
return HashCode.Combine(ID);
}
}
var chenrui = new Person
{
ID = 1,
Name = "陈1"
};
var sevenchen = new Person
{
ID = 1,
Name = "陈7"
};
Console.WriteLine($"chenrui equal sevenchen: {chenrui.Equals(sevenchen)}");//True
var set = new HashSet<Person>() { chenrui, sevenchen };
Console.WriteLine("=======HashSet=======");
// ID:1;Name:陈 1
foreach (var item in set)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
Console.WriteLine($"set contains chenrui: {set.Contains(chenrui)}");//True
Console.WriteLine($"set contains sevenchen: {set.Contains(sevenchen)}");//True
Console.WriteLine("=======List=======");
// ID:1;Name:陈 1
// ID:1;Name:陈 7
var list = new List<Person>() { chenrui, sevenchen };
foreach (var item in list)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}
Console.WriteLine($"list contains chenrui: {list.Contains(chenrui)}");//True
Console.WriteLine($"list contains sevenchen: {list.Contains(sevenchen)}");//True
Console.WriteLine("=======Distincted List=======");
// ID:1;Name:陈 1
var distinctedList = list.Distinct();
foreach (var item in distinctedList)
{
Console.WriteLine($"ID:{item.ID};Name:{item.Name}");
}注意
对象的 Equals 一定要搭配 GetHashCode使用。
IEqualityComparer
相对于IEquatable,IEqualityComparer一般作为判断相等的外部参数。 比如以下方式也可以实现判断:
class Person
{
public string Name { get; set; }
public int ID { get; set; }
}
public class PersonEqualityComparer : IEqualityComparer<Person>
{
bool IEqualityComparer<Person>.Equals(Person? x, Person? y)
{
return x != null && y != null && x.ID == y.ID;
}
int IEqualityComparer<Person>.GetHashCode(Person obj)
{
return HashCode.Combine(HashCode.Combine(obj.ID));
}
}
//作为参数
var set = new HashSet<Person>(new PersonEqualityComparer()) { chenrui, sevenchen };
//作为参数
var list = new List<Person>() { chenrui, sevenchen };
var distinctedList = list.Distinct(new PersonEqualityComparer());
//IEnumerable提供了另外的方法,可以将IEqualityComparer作为匿名方法(也称为 Lambda 表达式)
//此时可以不用实现Equals和GetHashCode
var distinctedList1 = list.DistinctBy((p) => p.ID);集合性能优化
参考性能优化